- Wed 20 December 2023
- ML Systems
- #ml-code, #llm, #ml-acceleration
Concept - Coalescing
Memory Coalescing is a fundamental performance consideration in HPC programming1 and provides another dimension for memory efficiency and how aligned versus misaligned memory accesses can significantly impact throughput.
The global memory of a CUDA device is implemented with DRAMs. Each time a DRAM location is accessed, a range of consecutive locations that includes the requested location is actually accessed. Many sensors are provided in each DRAM chip and they work in parallel. Each senses the content of a bit within these consecutive locations. Once detected by the sensors, the data from all these consecutive locations can be transferred at very high-speed to the processor. These consecutive locations accessed and delivered are referred to as DRAM bursts.
Recognizing the burst mechanism, current CUDA devices employ a technique that allows the programmers to achieve high global memory access efficiency by organizing memory access of threads into favorable patterns. This technique takes advantage of the fact that threads in a warp execute the same instruction at any given point in time (SIMT). When all threads in a warp execute a load instruction, the hardware detects whether they access consecutive global memory locations. If they do, the hardware combines, or coalesces, all these accesses into a consolidated access to consecutive DRAM locations. Such coalesced access allows the DRAMs to deliver data as a burst.
Memory Layout Semantics and Access Patterns
Programming languages provide abstract representations of matrices and arrays, but underneath these abstractions, memory is always linear. In C/C++ and CUDA, multidimensional arrays are typically stored in row-major order, meaning consecutive elements of a row occupy adjacent memory locations.
This becomes critically relevant in CUDA, where thread warps execute memory accesses in parallel. When threads within a warp access consecutive memory addresses, the hardware can coalesce those accesses into a single wide memory transaction. Misaligned or scattered accesses, by contrast, require independent transactions for each thread, resulting in substantial performance degradation.
Coalesced Access – The B Matrix
Consider the classic case of dense matrix multiplication2 When accessing the B matrix, each CUDA thread reads a distinct column. Since matrices are stored in row-major order, reading columns means accessing consecutive addresses along a row — which are adjacent in memory.
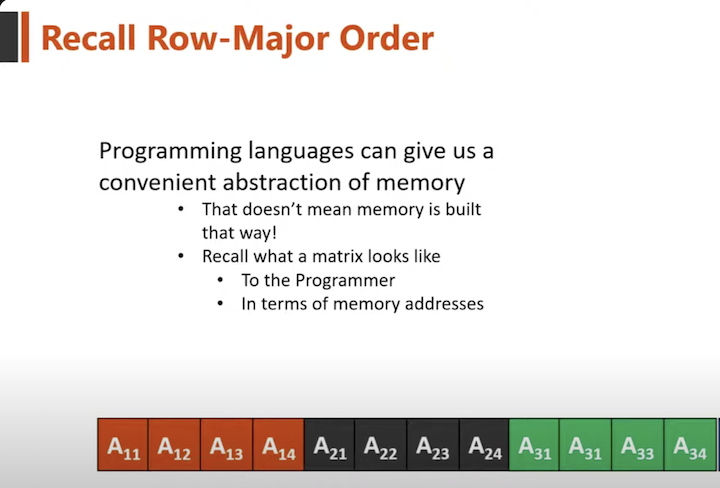
Image ref - CoffeeBeforeArch
This access pattern enables coalescing: instead of multiple separate memory reads, the GPU issues a single transaction that serves the entire warp. The result is reduced memory latency and improved effective bandwidth.
Misaligned Access – The A Matrix
In contrast, accessing the A matrix typically involves each thread reading a different row and iterating across columns. Due to row-major layout, rows are not adjacent in memory — they are separated by the width of the matrix.

Image ref - CoffeeBeforeArch
As a result, even if thread accesses are conceptually aligned in the matrix, they are thousands of elements apart in memory. These accesses are non-coalesced, forcing the hardware to issue multiple independent transactions per warp. This behavior incurs significantly higher latency and reduces throughput.
Optimization via Transposition
To address the misaligned access pattern in the A matrix, a simple yet effective transformation can be applied: pre-transposing the A matrix prior to the kernel launch. Transposition transforms rows into columns. When both A and B matrices are accessed along columns, all memory accesses become coalesced, optimizing memory throughput without introducing shared memory or tiling techniques. Implementation-wise, this requires updating index calculations inside the kernel. Rather than iterating over fixed rows, threads iterate across columns (mirroring the access pattern used for B)3.
TLDR;
- Row-major layout requires careful design of access patterns to ensure spatial locality4.
- Transposing input matrices can transform misaligned accesses into coalesced accesses.
- Profiling should always validate performance assumptions; even minor misalignments can incur major penalties.
- Optimization strategies must consider not only compute efficiency but also global memory bandwidth and access coalescing.
References
CoffeeBeforeArch Github Repository↩︎
CoffeeBeforeArch Youtube tutorial↩︎
https://homepages.math.uic.edu/~jan/mcs572f16/mcs572notes/lec35.html↩︎
https://medium.com/distributed-knowledge/cuda-memory-management-use-cases-f9d340f7c704↩︎
If you found this useful, please cite this post using
Senthilkumar Gopal. (Dec 2023). Concept - Coalescing. sengopal.me. https://sengopal.me/posts/concept-coalescing
or
@article{gopal2023conceptcoalescing,
title = {Concept - Coalescing},
author = {Senthilkumar Gopal},
journal = {sengopal.me},
year = {2023},
month = {Dec},
url = {https://sengopal.me/posts/concept-coalescing}
}